Mô hình ngôn ngữ lớn LLMs là các hệ thống trí tuệ nhân tạo tiên tiến, sử dụng kỹ thuật học sâu để xử lý, hiểu và tạo ra văn bản tương tự con người. Được huấn luyện trên lượng dữ liệu khổng lồ, LLMs có khả năng thực hiện nhiều nhiệm vụ ngôn ngữ phức tạp như dịch thuật, tóm tắt và tạo nội dung.
Mô hình ngôn ngữ lớn LLMs là gì?
Mô hình LLMs ngôn ngữ lớn (Large Language Model) là một loại mô hình máy học được huấn luyện trên lượng lớn dữ liệu văn bản để hiểu và tạo ra ngôn ngữ tự nhiên. Các mô hình này sử dụng các thuật toán tiên tiến để dự đoán từ tiếp theo trong một chuỗi văn bản, giúp chúng có khả năng thực hiện nhiều tác vụ ngôn ngữ như dịch thuật, trả lời câu hỏi, tóm tắt văn bản và thậm chí sáng tác văn học.
Cách hoạt động: Ngôn ngữ lớn (LLMs) sử dụng một kiến trúc mạng nơ-ron sâu, điển hình là Transformer, để xử lý dữ liệu văn bản. Chúng học từ dữ liệu đầu vào bằng cách xác định các mẫu và mối quan hệ giữa các từ và cụm từ. Quá trình huấn luyện đòi hỏi lượng tài nguyên tính toán lớn và có thể kéo dài hàng tuần hoặc hàng tháng, nhưng kết quả là một mô hình có khả năng hiểu và tạo ra văn bản với mức độ chính xác cao.
Ứng dụng Mô hình ngôn ngữ lớn LLMs
-
Dịch thuật tự động: Dịch văn bản từ ngôn ngữ này sang ngôn ngữ khác.
-
Tạo nội dung: Viết blog, bài báo, kịch bản và các tài liệu khác.
-
Trợ lý ảo: Trả lời câu hỏi và trợ giúp người dùng trong nhiều ngữ cảnh.
-
Tóm tắt văn bản: Tóm lược các tài liệu dài thành các đoạn văn ngắn gọn và dễ hiểu.
Khi các LLM (Large Language Model) tiếp tục phát triển, chúng có tiềm năng lớn để tăng cường và tự động hóa nhiều ứng dụng trong các lĩnh vực khác nhau, từ dịch vụ khách hàng và sáng tạo nội dung đến giáo dục và nghiên cứu. Tuy nhiên, chúng cũng đặt ra các thách thức về đạo đức và xã hội, chẳng hạn như sự thiên vị hoặc lạm dụng, cần được giải quyết khi công nghệ tiến bộ.

Tinh chỉnh mô hình LLMs chuyên biệt với OnGPT
OnGPT là một nền tảng giúp doanh nghiệp và cá nhân tạo ra các chatbot AI chuyên biệt bằng cách sử dụng dữ liệu của chính họ. OnGPT cho phép tinh chỉnh các mô hình ngôn ngữ lớn để phù hợp với ngữ cảnh và yêu cầu cụ thể của từng khách hàng.
Quy trình tinh chỉnh LLMs
-
Thu thập dữ liệu: Xác định và thu thập các tài liệu và dữ liệu liên quan đến lĩnh vực mà bạn muốn mô hình ngôn ngữ hỗ trợ.
-
Huấn luyện mô hình: Sử dụng dữ liệu đã thu thập để tinh chỉnh mô hình ngôn ngữ lớn, giúp nó hiểu và xử lý thông tin tốt hơn trong ngữ cảnh cụ thể của bạn.
-
Triển khai và kiểm tra: Sau khi huấn luyện, triển khai mô hình vào các ứng dụng thực tế và kiểm tra hiệu suất của nó. Điều chỉnh thêm nếu cần thiết để đảm bảo mô hình hoạt động hiệu quả.
Lợi ích của việc tinh chỉnh với OnGPT
-
Tối ưu hóa hiệu suất: Mô hình được tinh chỉnh để hiểu và phản hồi chính xác hơn trong ngữ cảnh cụ thể của doanh nghiệp.
-
Tiết kiệm thời gian và chi phí: OnGPT giúp giảm bớt khối lượng công việc cần thiết để phát triển một mô hình ngôn ngữ từ đầu.
-
Cải thiện trải nghiệm người dùng: Chatbot AI chuyên biệt có thể cung cấp câu trả lời nhanh chóng và chính xác, nâng cao sự hài lòng của khách hàng.
Ví dụ ứng dụng
-
Chăm sóc khách hàng: Chatbot hỗ trợ khách hàng giải quyết các vấn đề và trả lời câu hỏi một cách hiệu quả.
-
Tư vấn tài chính: Mô hình ngôn ngữ chuyên biệt có thể cung cấp lời khuyên tài chính dựa trên dữ liệu và xu hướng thị trường hiện tại.
-
Giáo dục: Trợ giúp học sinh và giáo viên với các bài giảng, câu hỏi ôn tập và tài liệu học tập.
OnGPT giúp tận dụng sức mạnh của mô hình LLM ngôn ngữ lớn để tạo ra các giải pháp AI tùy chỉnh, đáp ứng nhu cầu cụ thể của từng doanh nghiệp, từ đó cải thiện hiệu quả hoạt động và trải nghiệm người dùng.

Các yếu tố cần thiết trong mô hình ngôn ngữ lớn LLMs
Để đào tạo thành công các mô hình ngôn ngữ lớn (LLM), cần phải xây dựng một kho dữ liệu toàn diện. Quá trình này đòi hỏi việc thu thập một lượng dữ liệu khổng lồ và đảm bảo chất lượng cũng như mức độ liên quan cao. Dưới đây là những khía cạnh quan trọng ảnh hưởng đến việc phát triển một thư viện dữ liệu hiệu quả cho việc đào tạo mô hình ngôn ngữ.
Ưu tiên chất lượng dữ liệu bên cạnh số lượng
Một tập dữ liệu lớn là nền tảng cho việc đào tạo các mô hình ngôn ngữ, nhưng chất lượng dữ liệu cũng đóng vai trò vô cùng quan trọng. Mô hình được huấn luyện trên dữ liệu phong phú nhưng không được tổ chức tốt có thể mang lại kết quả thiếu chính xác. Ngược lại, các bộ dữ liệu nhỏ hơn nhưng được quản lý tỉ mỉ thường mang lại hiệu suất vượt trội. Do đó, cần có sự cân bằng giữa việc thu thập dữ liệu đại diện, đa dạng và phù hợp với mục tiêu của mô hình thông qua quá trình lựa chọn, làm sạch và sắp xếp dữ liệu cẩn thận.
Việc lựa chọn nguồn dữ liệu cần phải phù hợp với mục tiêu ứng dụng cụ thể của mô hình. Ví dụ:
- Các mô hình tạo ra đối thoại sẽ được hưởng lợi từ các nguồn như cuộc trò chuyện và phỏng vấn.
- Các mô hình tập trung vào việc tạo mã sẽ hưởng lợi từ các kho mã được ghi chép đầy đủ.
- Các tác phẩm văn học và kịch bản cung cấp nhiều tài liệu đào tạo cho các mô hình hướng tới mục tiêu viết sáng tạo.
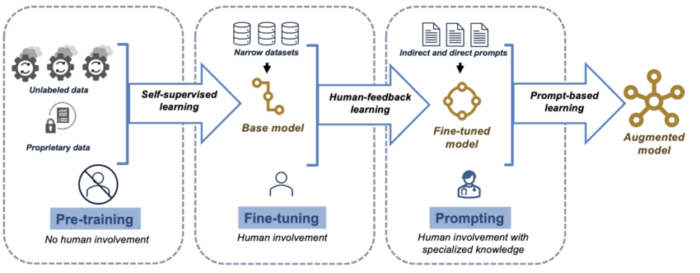
Sử dụng tính năng tạo dữ liệu tổng hợp: Cải thiện tập dữ liệu của bạn bằng dữ liệu tổng hợp có thể lấp đầy khoảng trống và mở rộng phạm vi của nó. Tăng cường dữ liệu, sử dụng mô hình tạo văn bản và tạo dữ liệu dựa trên quy tắc để tạo ra dữ liệu nhân tạo phản ánh các mẫu trong thế giới thực. Chiến lược này tăng cường tính đa dạng của tập huấn luyện, nâng cao khả năng phục hồi của mô hình và giúp giảm bớt thành kiến. Đảm bảo chất lượng của dữ liệu tổng hợp để nó đóng góp tích cực vào khả năng hiểu và tạo ngôn ngữ của mô hình trong miền mục tiêu.
Triển khai thu thập dữ liệu tự động: Tự động hóa quy trình thu thập dữ liệu giúp tích hợp nhất quán dữ liệu mới và phù hợp. Sử dụng các công cụ quét web, API và khung nhập dữ liệu để thu thập các tập dữ liệu khác nhau một cách hiệu quả. Tinh chỉnh các công cụ này để tập trung vào dữ liệu chất lượng cao và liên quan, tối ưu hóa tài liệu đào tạo cho mô hình. Cần liên tục giám sát các hệ thống tự động này để duy trì tính chính xác và tính liêm chính về mặt đạo đức của chúng.
Kết luận
Xây dựng kho dữ liệu cho LLM là một quá trình phức tạp đòi hỏi sự kết hợp giữa thu thập lượng lớn dữ liệu và đảm bảo chất lượng cao. Việc chọn lọc nguồn dữ liệu phù hợp, sử dụng dữ liệu tổng hợp, và triển khai tự động hóa thu thập dữ liệu là những bước quan trọng để phát triển mô hình ngôn ngữ hiệu quả và đáng tin cậy.


